
GitHub Pages is one of the most popular tools for developers when it comes to static site hosting. But what if the contents didn't have to be completely static? In this post I'll outline how you can make a dynamic website powered by GitHub Pages and GitHub Actions and explain the nuts and bolts of how it works. Best of all, this works with just a free GitHub account!
If you're someone who wants to cut to the chase and see what can be built, I made:
- A simple image upload site,
- A simple pastebin clone and
- Integrated this solution into my earnings tracker website, where you can submit other companies to be added to the earnings lists without any sign in.
Combinging GitHub Actions and Pages
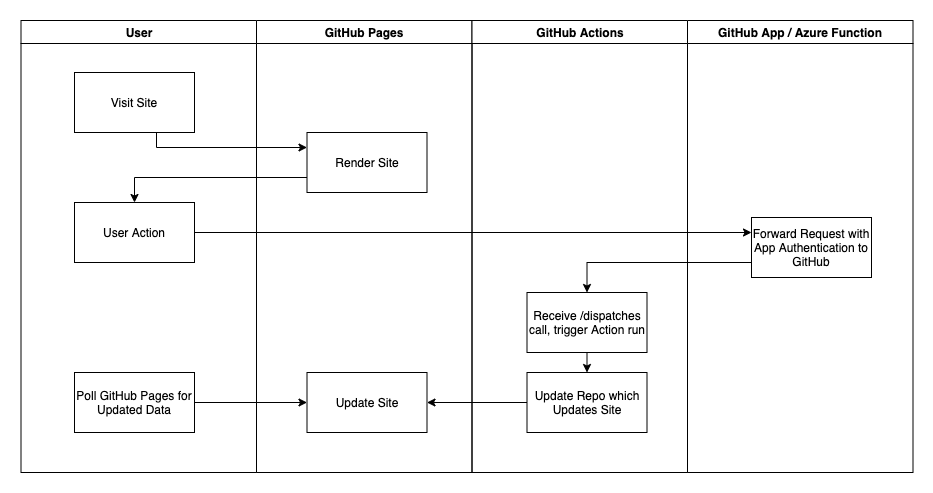
GitHub allows you to create actions in your repository, these are basically CI flows that can (among other things) make changes to files and commit them back to the repository. You can trigger an action run by one of many ways, but in this post we'll focus on repository_dispatch, which allows you to trigger an action from a HTTP request to a GitHub API endpoint.
On GitHub, you can also convert your repository into a full-blown static website for free using GitHub Pages.
It's not hard to imagine when combining these two features of GitHub that you could make a flow of data such that your GitHub Pages website:
- Makes a HTTP call to trigger an action run
- That action run then updates the repo and
- The repo update updates the GitHub authentication.
There is however one barrier to this approach, authentication.
Triggering an action with repository_dispatch requires you to pass a bearer token. You can create a PAT (Personal Access Token) and use that, however if you were to publish that on your GitHub Pages site it would give any visitor the ability to modify all of your repos on GitHub. So until GitHub add tighter scoping controls (ideally a specific repo and only permission to run actions) we have to use the other option, a GitHub App.
I've created a GitHub app to support this flow, including the Azure function necessary to proxy the requests to GitHub. This allows you to delegate permission for action runs on a specific repo to the GitHub app, and then make API calls to it's public-facing Azure function endpoint to trigger a repository_dispatch event. If you want to spin up your own version of the app/function, source is available here.
What is Now Possible
Roughly the steps are as follows:
- Install the GitHub app to your repo to allow
repository_dispatchto be called unauthenticated. - Add a fetch call (like below) as part of some user action on the GitHub Pages site itself.
- Create a GitHub action in the same repo that accepts a repository_dispatch trigger (triggered by the fetch call), modify some data, commit it back to the repository that will update the GitHub Pages site. Make sure the commit and push step handles rebasing to allow for concurrent runs and add some retry steps in case the rebase push fails.
fetch("https://publicactiontrigger.azurewebsites.net/api/dispatches/{owner}/{repo}", {
method: 'POST',
mode: 'cors',
body: JSON.stringify({ event_type: 'some-event', client_payload: { data: 'somedata' } })
});
For those of you that prefer technically incorrect but kind of legible diagrams, this is what is happening behind the scenes:
Limitations
GitHub Pages and GitHub Actions weren't exactly designed with this use-case in mind, as such there are some limitations you'll run into:
- Updates aren't instant. The action can often take 5-10 seconds to kick off, then depending on what your action does it may take 30 seconds to run, then another 10-30 seconds for GitHub Pages to reflect the repo changes.
- Payload sizes are limited. The maximum size of a payload you can send to the /dispatches endpoint is limited by GitHub to ~70kb. Here is my ask about making this bigger.
- Reflecting updates requires cache-busting. The only way for the users session to know if the action has taken effect is to request a file it knows will be changed once the action run is complete with a different query string parameter repeatedly. A simple way to do this is to pass a known ID (e.g. a GUID) to the dispatch call and then write that to a file in the served pages directory. When you repeatedly ping that file from the client and get a 200 response back you know the action run has succeeded.
- Parallel actions are capped at 20. If your actions run as fast as 10 seconds, you can fit a maximum of ~120 updates per minute. However if you receive a burst of user actions there is potential that some will be dropped and ignored by GitHub (or run later, I'm not sure how GitHub handles the concurrency limit). You may also run into scale issues trying to concurrently push a bunch of commits since the push will fail if the HEAD has been updated from the push in another action run, retries can help mitigate this.
- Making concurrent changes to the same file can be challenging. Because these updates run independently on separate Action runners, if they both modify a file at the same time, the commit and push step at the end may fail due to a conflict. I'll outline possible solutions to this below.
- All
repostitory_disaptchactions are publicly available unauthenticated. This means that this architecture is generally geared towards websites where there are no formal accounts for users and everything is publicly accessible.
Handling Concurrency
If all you want is a flat-file database to be updated, say a big JSON file or an SQLite database, you will likely run into conflicts when two updates happen at the same time. Here are a couple of approaches you can take:
Pushing Forward with a Single File
One potential solution to this is to create several retry steps. Such that if you hit a conflict on the push step, you clone the repo and run the update all over again. This isn't optimal as it doesn't guarantee the changes will eventually be made (all retries could fail), but this could ease some of the burden.
Redesigning Your Architecture as Unique Files
If the type of updates you are doing can be done independently of each other, you can write to different files and your actions won't conflict with each other. This is great for cases where users take some action and it can live independently of actions from other users. This is how the image uploader example works.
Taking Advantage of Jekyll Collections
A nice mix of separate files + listing them on a webpage can be done using Jekyll. Jekyll is built into GitHub Pages and you can use some of it's features to list collections of data on a webpage. This is the approach taken in the pastebin clone I built, where you can view a listing of all public pastes.
What's Possible
This aproach opens up a whole new type of website that can be created with GitHub Pages. Here are a couple ideas for fun ones that come to mind:
- Text sharing - i.e. Pastebin / GitHub Gists
- Image sharing (of small images) - i.e. Imgur (although trying to create a homepage/search gets tricky with concurrency, image upload is easy)
- Persisted website prototyping - i.e. Codepen / JSfiddle
- Persisted publicly editable music library - i.e. Stretto (disclaimer: another one of my open source projects)
- r/place clone (although the concurrent throughput may be an issue for a 1000x1000px grid).
In the Wild
It would be awesome to hear what you manage to create with this approach. Create an issue here to let me know how it goes.
